By Caitlin Burns, DocsCorp Content Manager.
By Caitlin Burns, DocsCorp Content Manager.
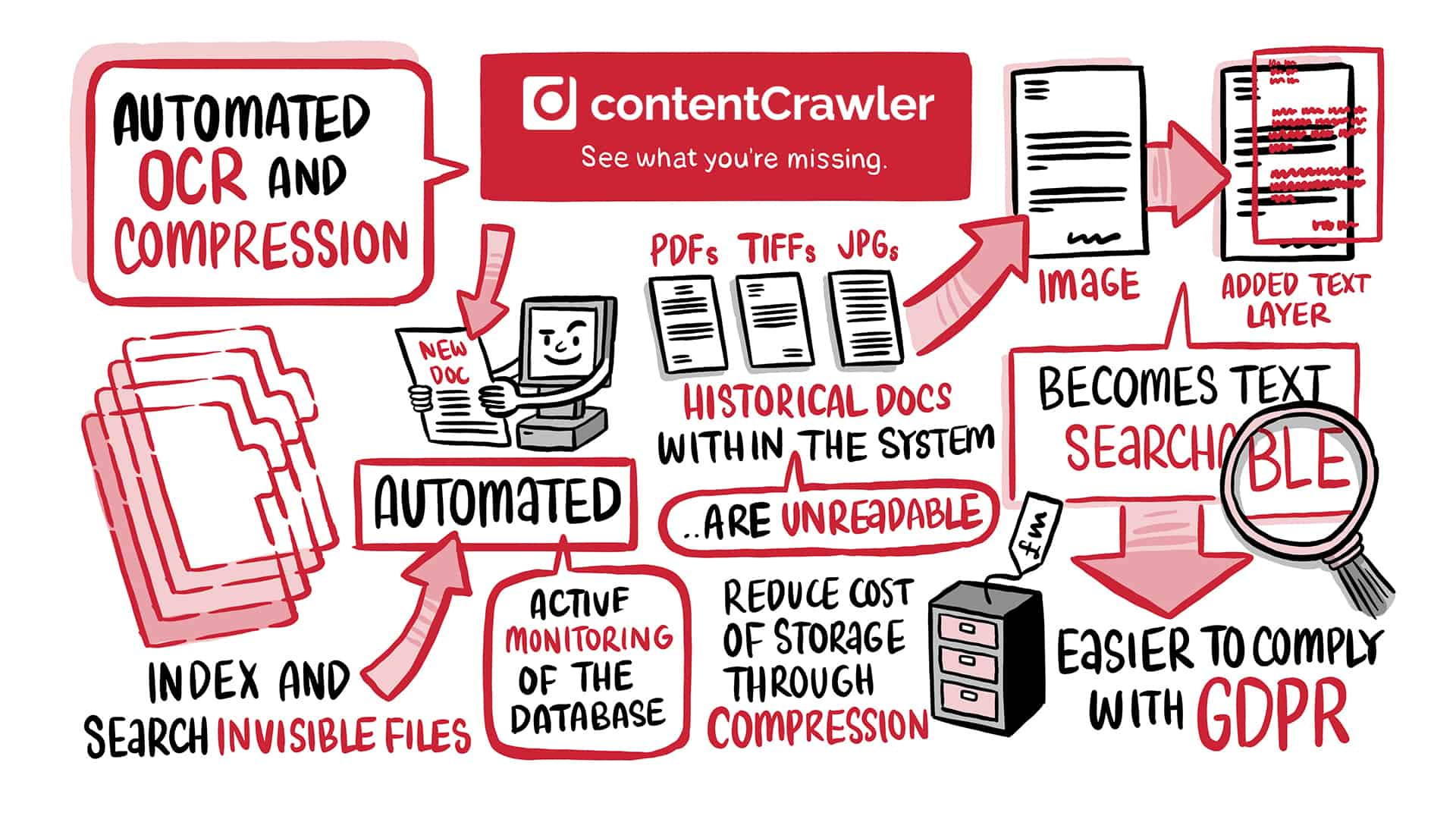
Many PDFs are created via a process that stores just an image of the document (like a photograph of the page).
For example, if a document is received from a scanner, it may only be an image of the document and contain no searchable text.
There is no text information in a scanned document that a user can search for, just millions of dots on a page of various colors and shades representing an image of the document.
There is no immediately simple way of determining if a PDF document is text-searchable. It can only be done by trial and error.
If you were to open a document that is not text-searchable, any text you entered in the Find field would not be found in the document. If you try to select text in the document, the entire page is selected.
How does OCR software make searchable PDFs?
PDFs that contain only images of a page of text are made searchable by a process called Optical Character Recognition (OCR). This involves a software application looking at all the dots on a page and determining what text characters are represented by those dots, including the font type, style, and size.
The better the image quality, the more accurate this process. 99% accuracy is possible for typical typewritten pages that are scanned. However, handwritten text cannot be understood unless very clearly written. The OCR process ignores graphics it can’t determine as text.
The process of OCRing a document in no way affects the images. When you view or print a document after OCRing, it looks the same, with the image retaining its graphics, pen marks, signatures, etc.
If you annotated the document with comments, highlighting, etc., these components remain on the page as before.
In some cases, the OCR software must approximate the font size, type, and style and may not find the exact font that the document was created with. Then, the text you select or Find may NOT line up precisely with the image of the text, but the OCR software can match it very closely.
Automated OCR software creates searchable PDFs using the following process:
1. It analyzes PDFs to determine if they contain text (or if the quantity of text characters found is less than a specific number of characters per page)
2. Using OCR technology, it creates and applies a text layer to non-searchable PDFs
3. It also converts image documents (BMP, JPEG, PNG, and TIFF) to text-searchable PDFs while retaining all their original image content
Learn more about contentCrawler for a set-and-forget solution to make searchable PDFs.
Related